STSR: High-Fidelity Speech Super-Resolution via Spectral-Transient Context Modeling
Abstract
Speech super-resolution (SR) requires a delicate balance between preserving global harmonic coherence and sharp local transients. While diffusion-based models achieve impressive fidelity, their computational demands limit practical use; conversely, efficient time-domain architectures often struggle to capture the long-range spectral dependencies essential for precise harmonic alignment. We introduce STSR, an end-to-end MDCT-domain framework designed to bridge this gap. STSR leverages a Spectral-Contextual Attention mechanism with hierarchical windowing to aggregate non-local context, ensuring consistent harmonic restoration up to 48 kHz. To prevent the loss of transient clarity in compressed spectral representations, we incorporate a sparse-aware regularization strategy. Experimental results demonstrate that STSR surpasses state-of-the-art baselines in both perceptual quality and zero-shot generalization, establishing a robust, real-time paradigm for high-fidelity speech restoration.
Comparisons with State-of-the-Art (SOTA) models on data files from VCTK-Test.
p360_002 (8 kHz -> 48 kHz)
Ground Truth LR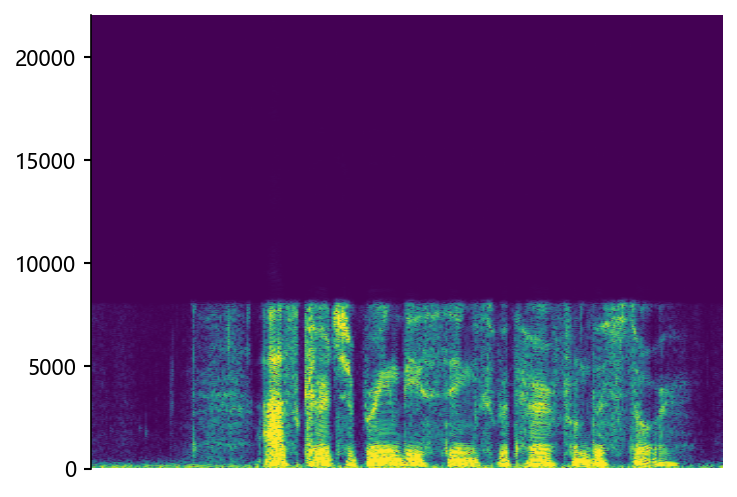
|
NU-Wave2
|
NVSR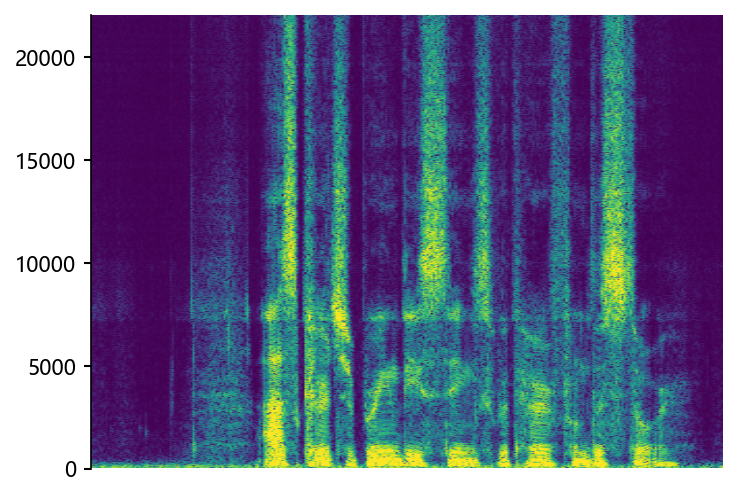
|
mdctGAN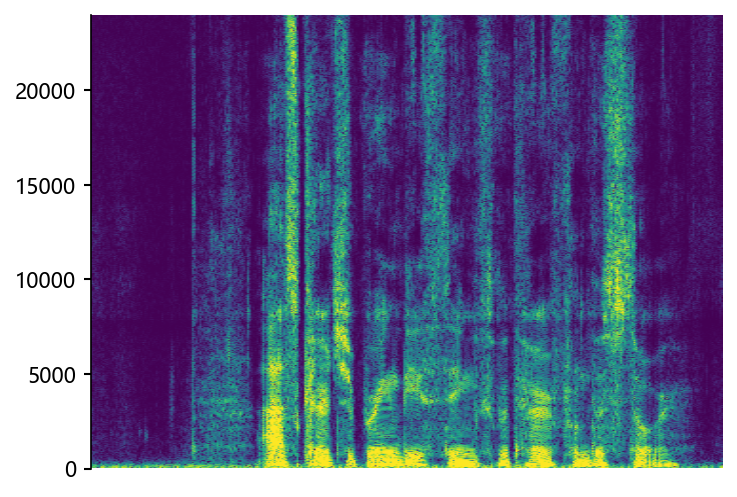
|
STSR (Proposed)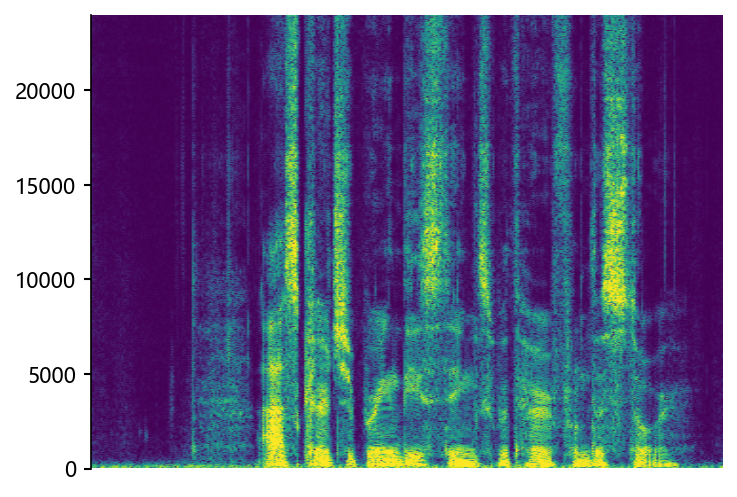
|
Ground Truth HR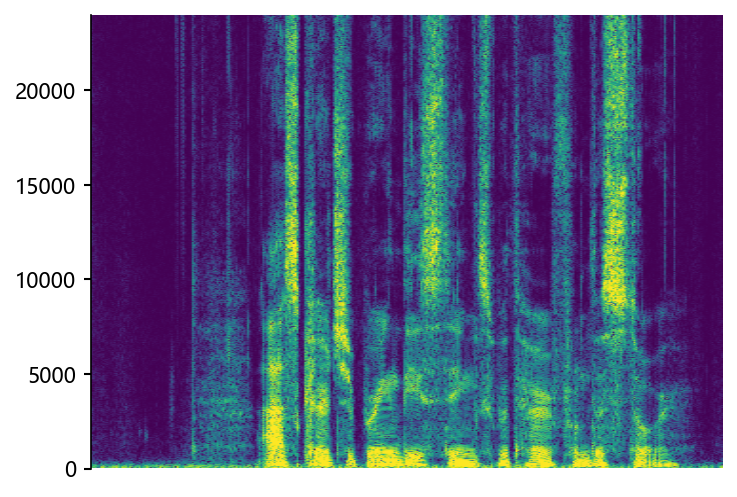
|
p374_002 (8 kHz -> 48 kHz)
Ground Truth LR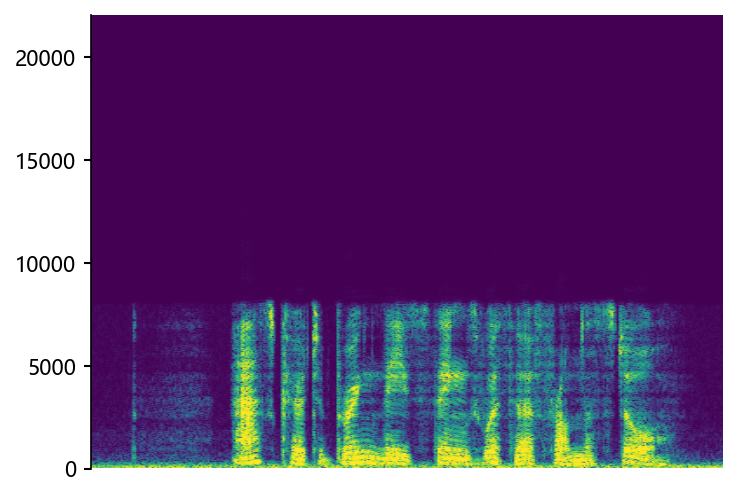
|
NVSR
|
mdctGAN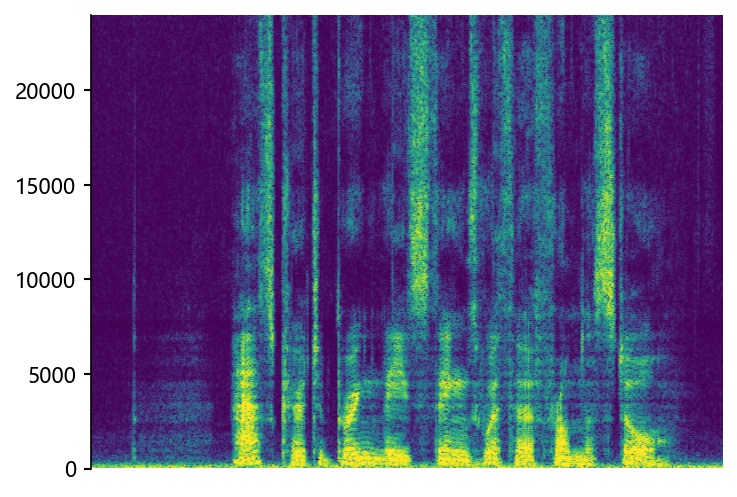
|
HiFi-SR
|
STSR (Proposed)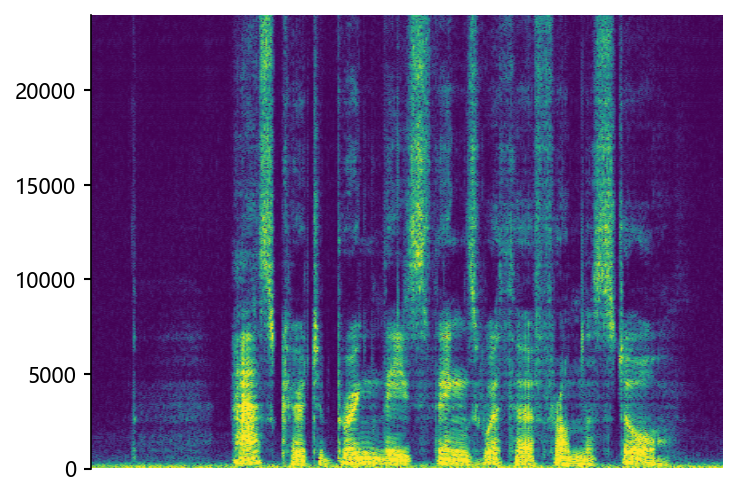
|
Ground Truth HR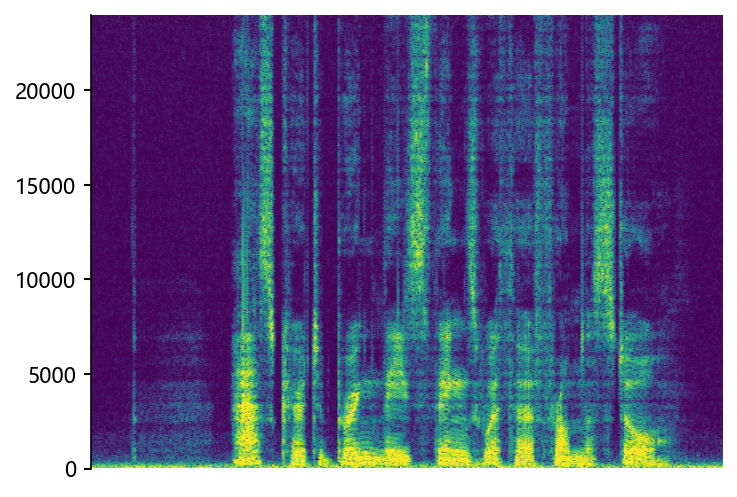
|
p360_008 (12 kHz -> 48 kHz)
Ground Truth LR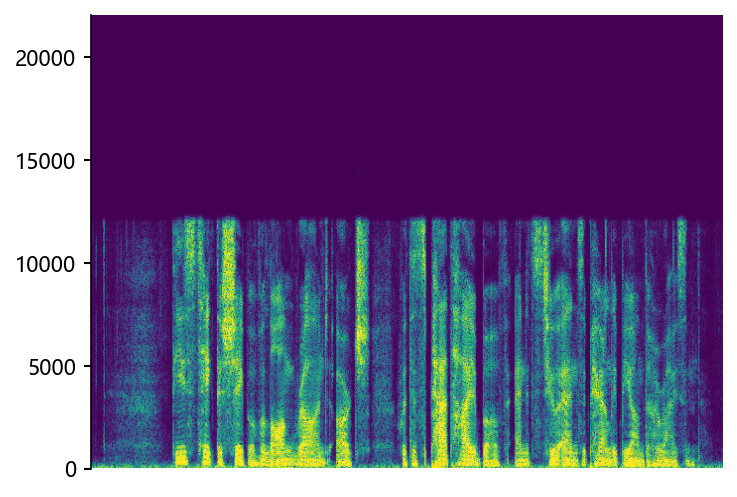
|
NU-Wave2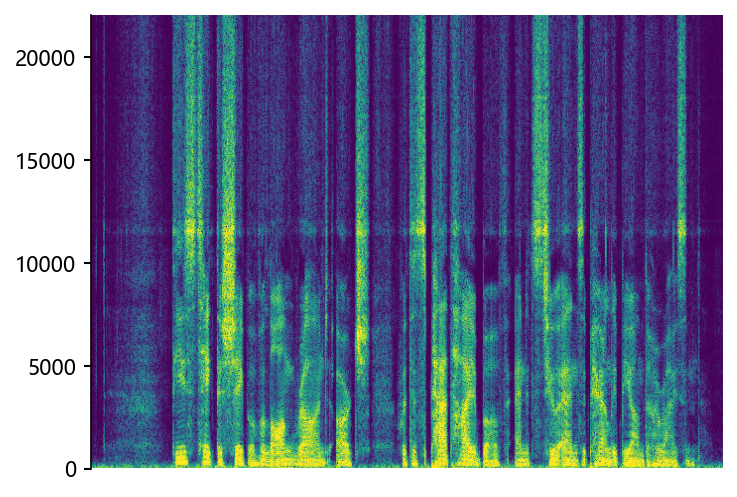
|
NVSR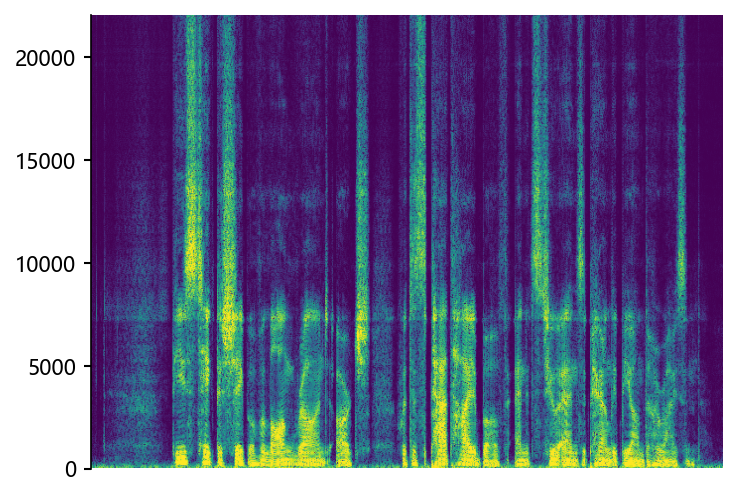
|
HiFi-SR
|
STSR (Proposed)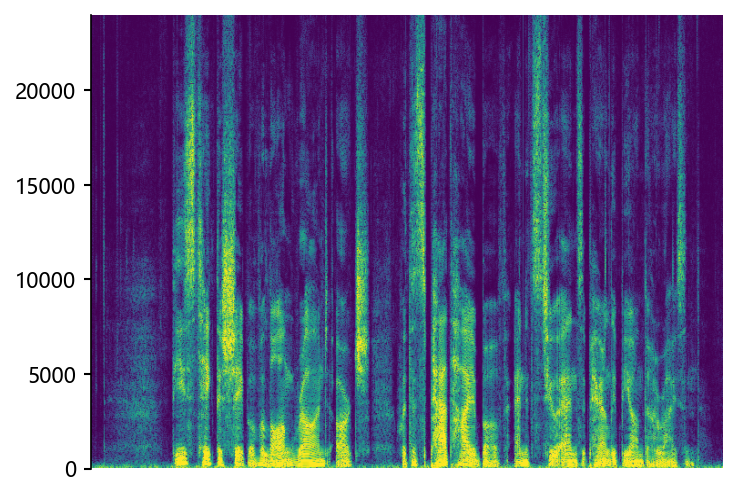
|
Ground Truth HR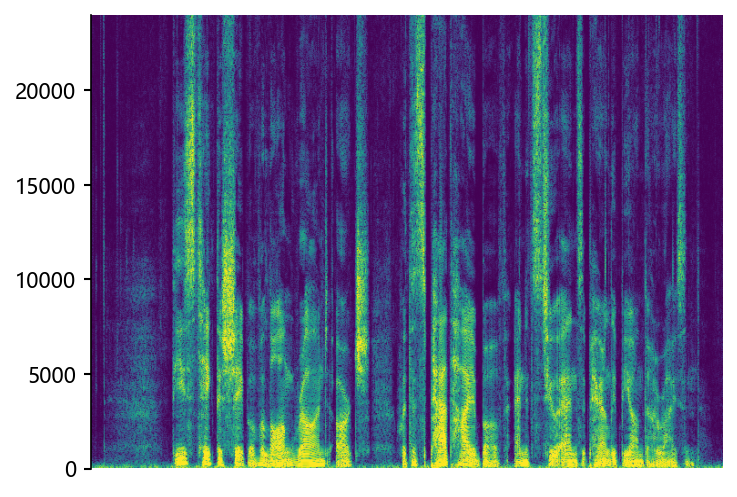
|
p376_007 (12 kHz -> 48 kHz)
Ground Truth LR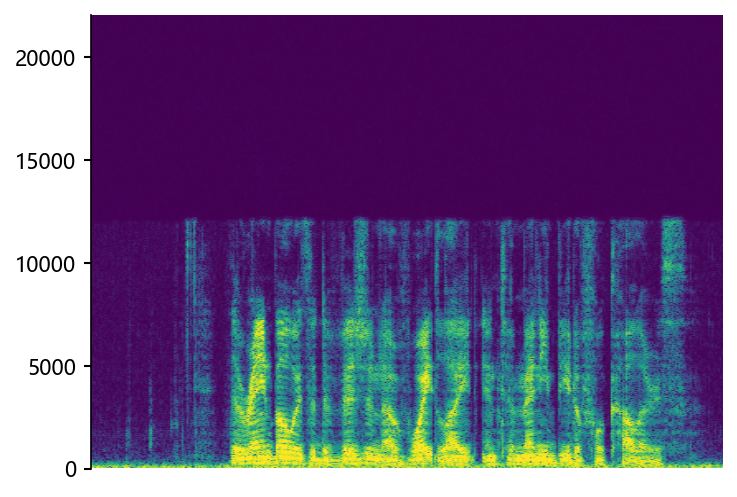
|
NU-Wave2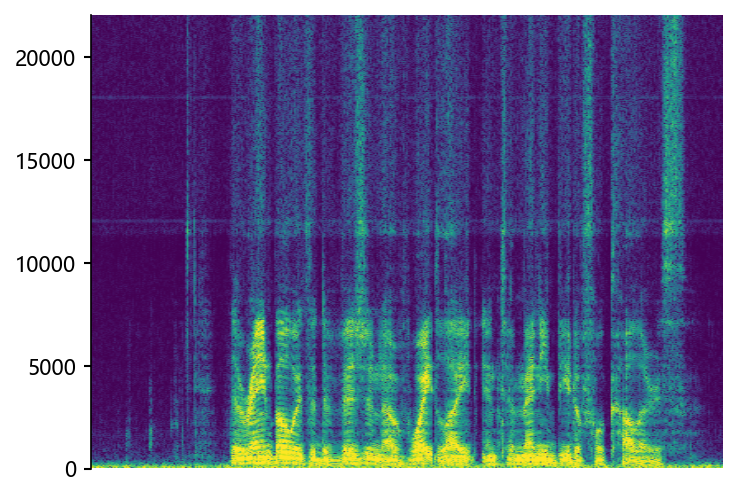
|
NVSR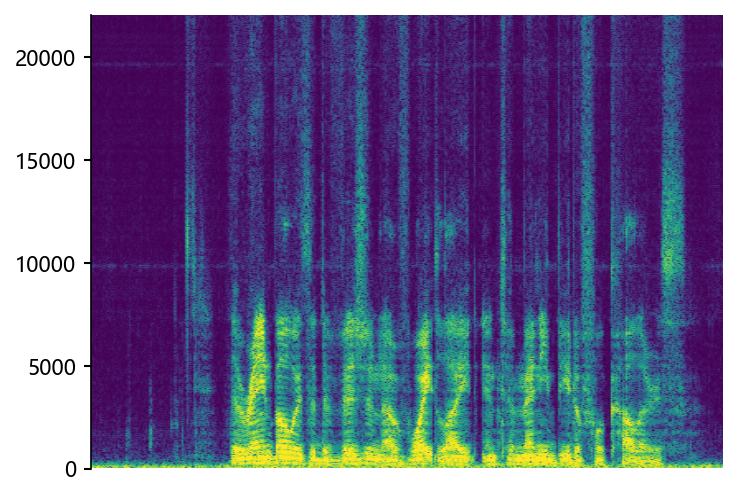
|
mdctGAN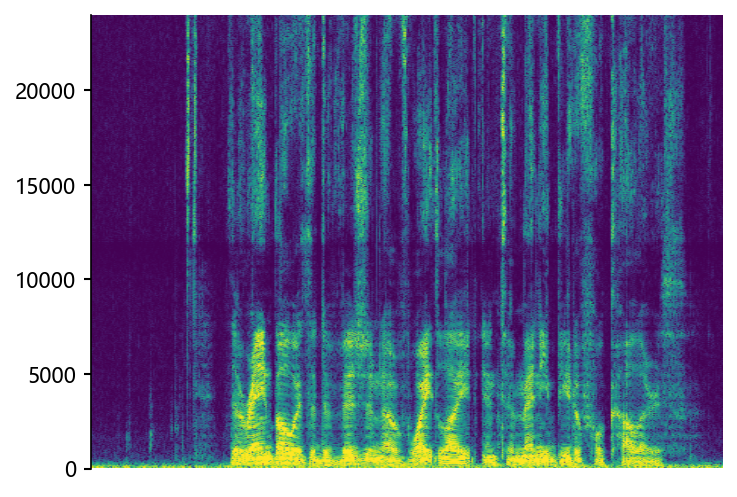
|
STSR (Proposed)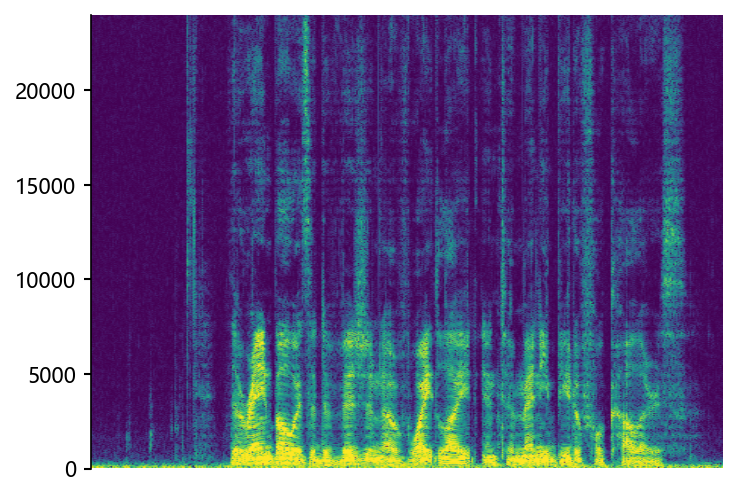
|
Ground Truth HR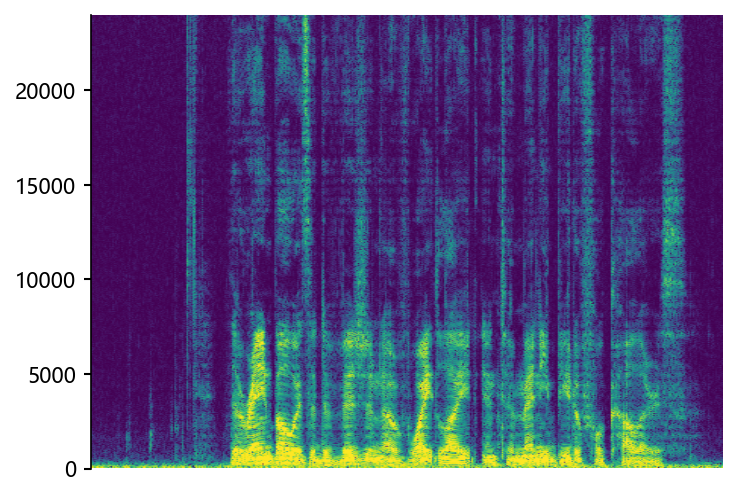
|
Example of bandwidth case on HiFi-TTS dataset
wonderfuladventures_19_seacole_0084 (8 kHz -> 48 kHz)
Ground Truth LR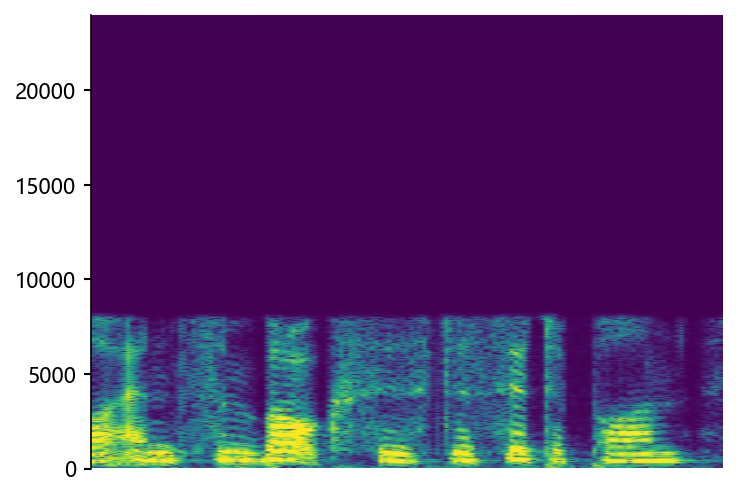
|
STSR (Proposed)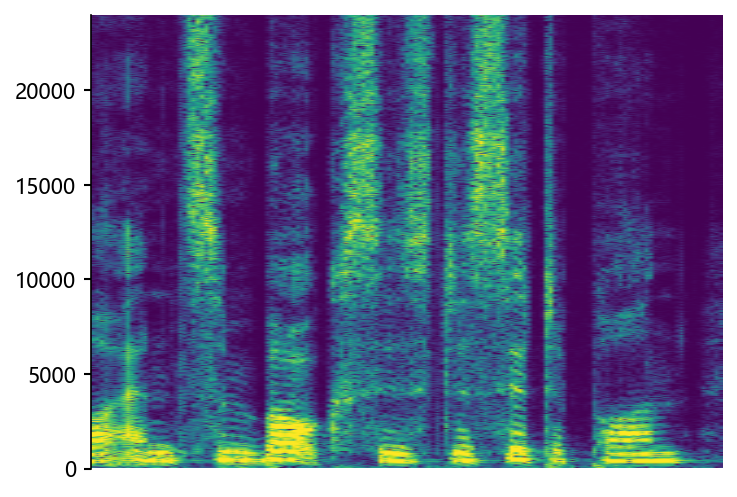
|
Ground Truth HR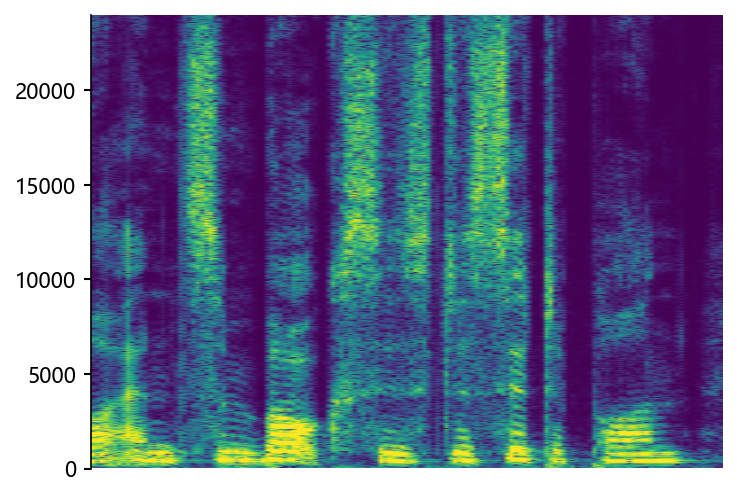
|
wonderfuladventures_19_seacole_0085 (8 kHz -> 48 kHz)
Ground Truth LR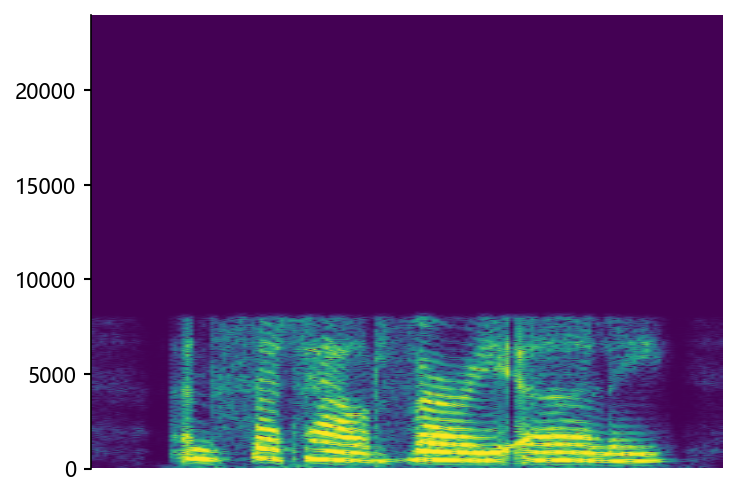
|
STSR (Proposed)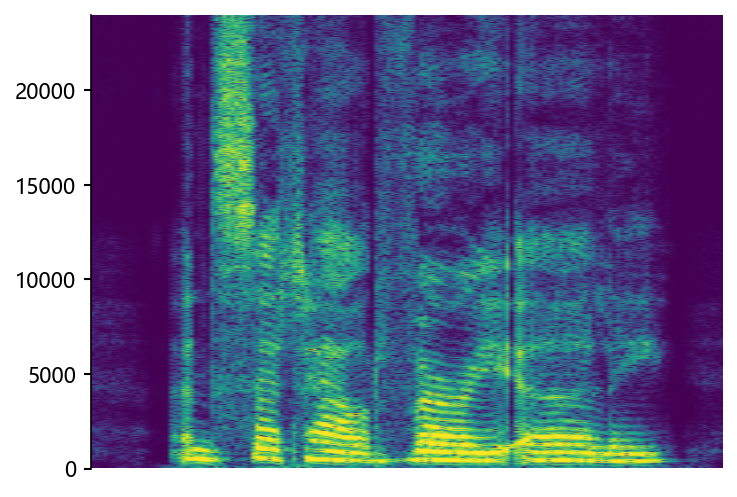
|
Ground Truth HR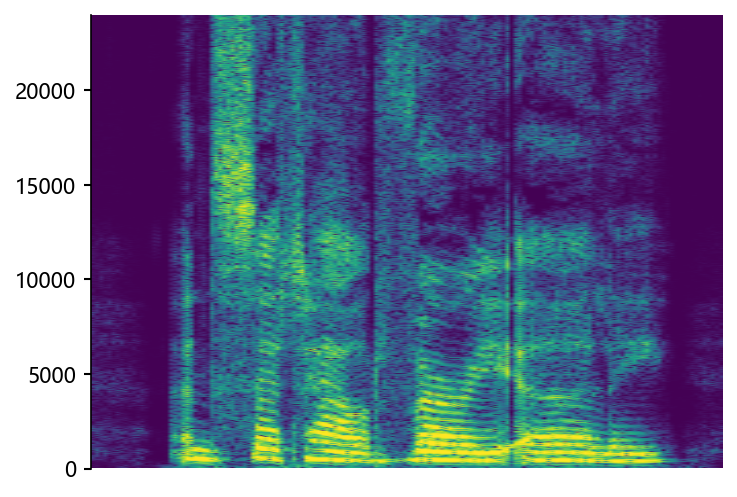
|